CompTIA DY0-001 Exam Price | DY0-001 Reliable Test Voucher
Wiki Article
P.S. Free & New DY0-001 dumps are available on Google Drive shared by VCEDumps: https://drive.google.com/open?id=1DjqMfz_GyalqsFXoW29_l6qOyMxFJdB3
As is known to us, getting the newest information is very important for all people to pass the exam and get the certification in the shortest time. In order to help all customers gain the newest information about the DY0-001 exam, the experts and professors from our company designed the best DY0-001 Study Materials. The IT experts will update the system every day. If there is new information about the exam, you will receive an email about the newest information about the DY0-001 study materials.
CompTIA DY0-001 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
>> CompTIA DY0-001 Exam Price <<
Professional DY0-001 Exam Price | Newest DY0-001 Reliable Test Voucher and Correct CompTIA DataAI Certification Exam Actual Exams
As the old saying goes people change with the times. People must constantly update their stocks of knowledge and improve their practical ability. Passing the test DY0-001 certification can help you achieve that and buying our DY0-001 test practice materials can help you pass the DY0-001 test smoothly. Our DY0-001 study question is superior to other same kinds of study materials in many aspects. Our DY0-001 test bank covers the entire syllabus of the test and all the possible questions which may appear in the test. You will pass the DY0-001 exam for sure.
CompTIA DataAI Certification Exam Sample Questions (Q62-Q67):
NEW QUESTION # 62
A company created a very popular collectible card set. Collectors attempt to collect the entire set, but the availability of each card varies, with because some cards have higher production volumes than others. The set contains a total of 12 cards. The attributes of the cards are below:
A data scientist is provided a historical record of cards purchased, which was acquired by a local collectors' association. The data scientist needs to design an initial model iteration to predict whether or not the animal on the card lives in the sea or on land given the provided attributes. Which of the following is the best way to accomplish this task?
- A. Association rules
- B. ARIMA
- C. Decision trees
- D. Linear regression
Answer: C
Explanation:
You have categorical inputs (wrapper color, shape, animal) and a binary target (sea vs. land). A decision tree natively handles categorical features and yields clear, rule-based splits that predict habitat, making it the most appropriate choice.
NEW QUESTION # 63
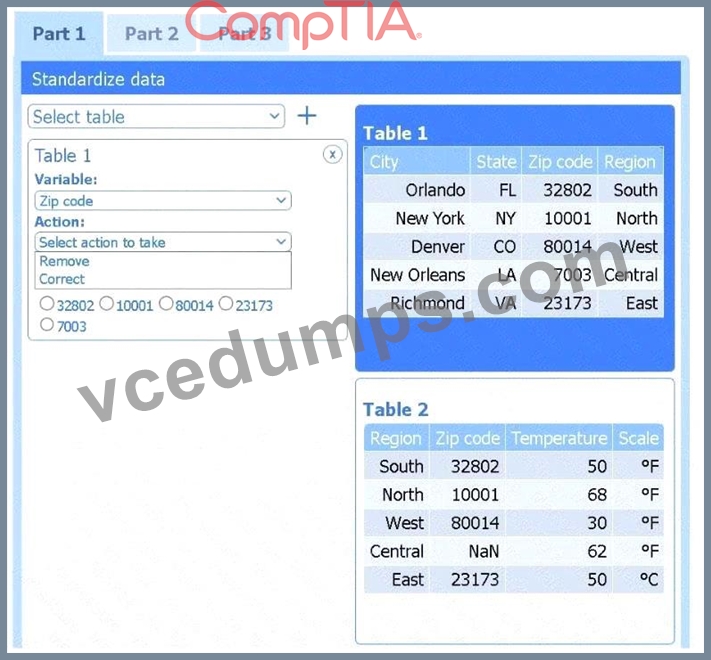
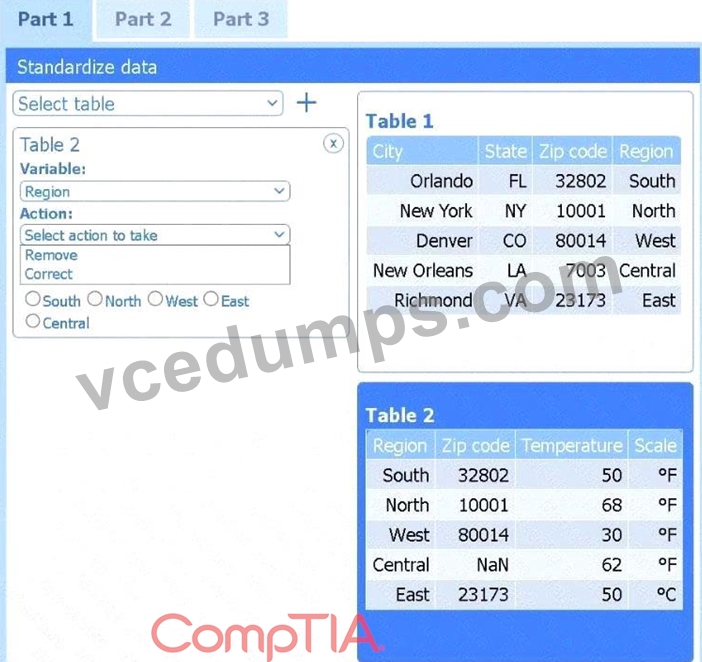
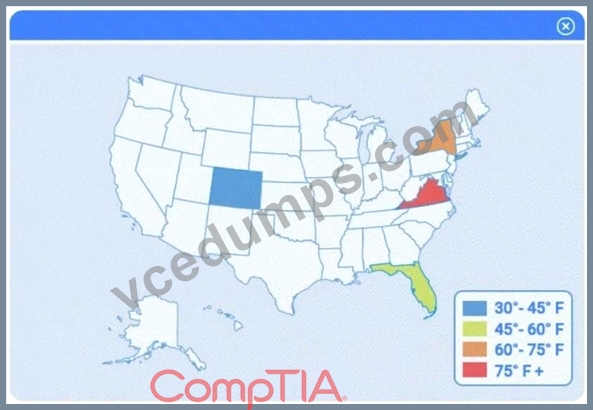
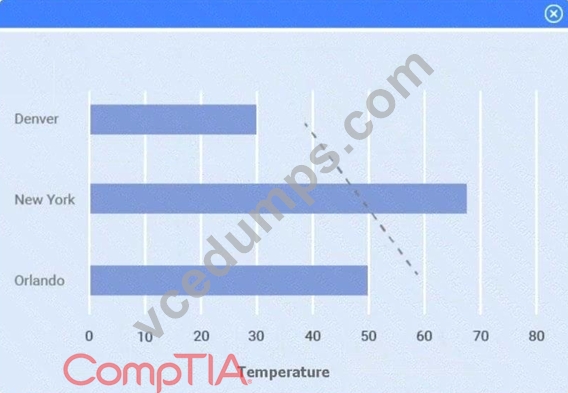
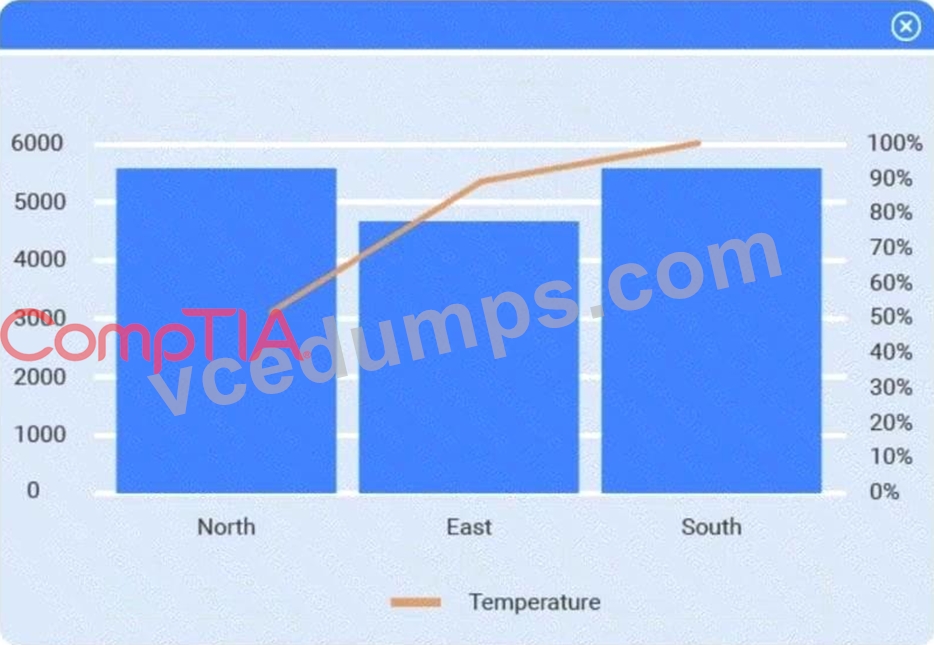
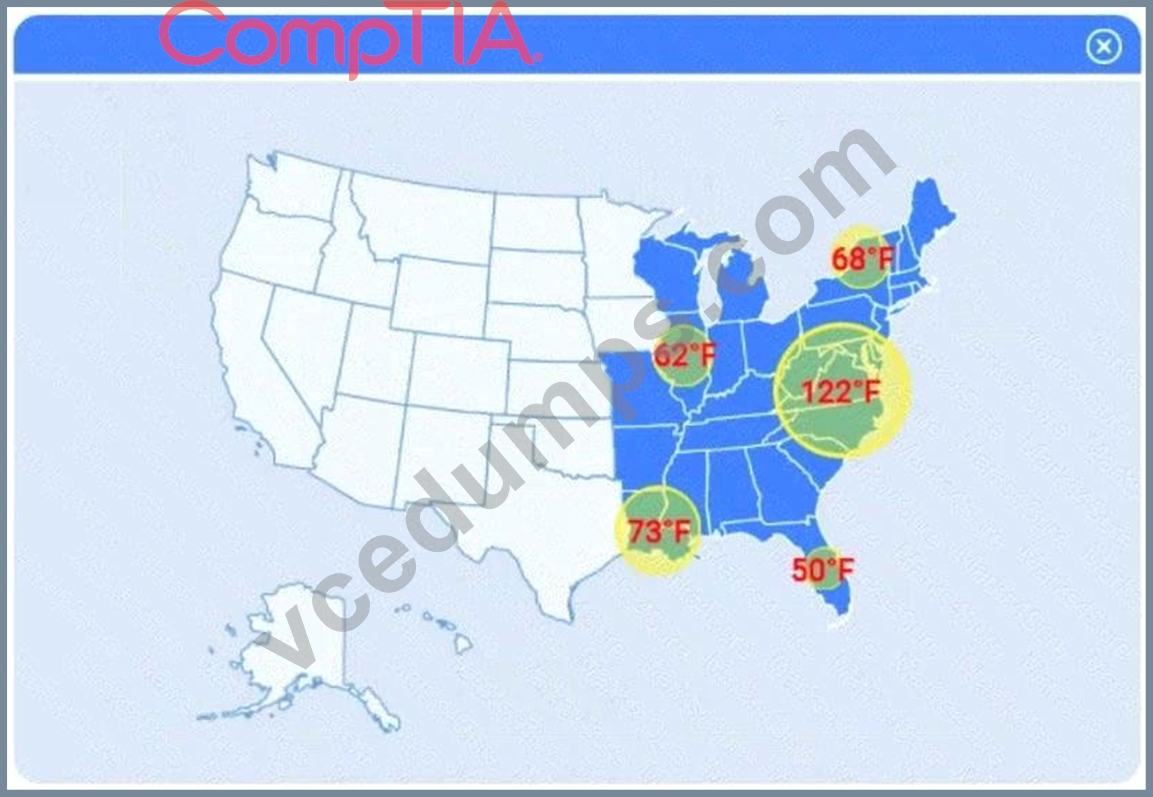
A client has gathered weather data on which regions have high temperatures. The client would like a visualization to gain a better understanding of the data.
INSTRUCTIONS
Part 1
Review the charts provided and use the drop-down menu to select the most appropriate way to standardize the data.
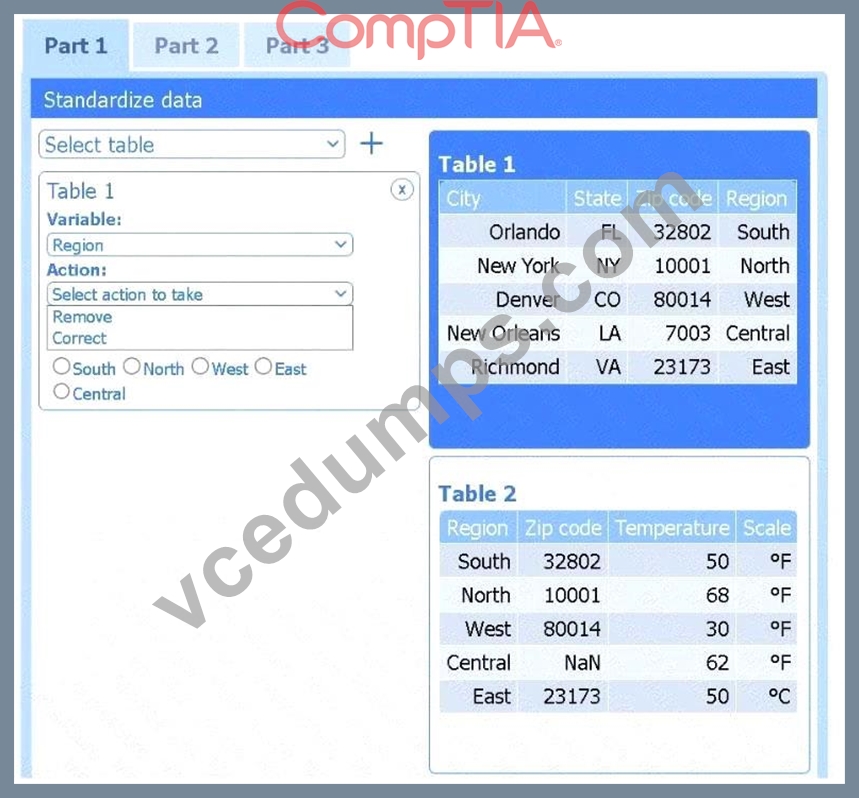
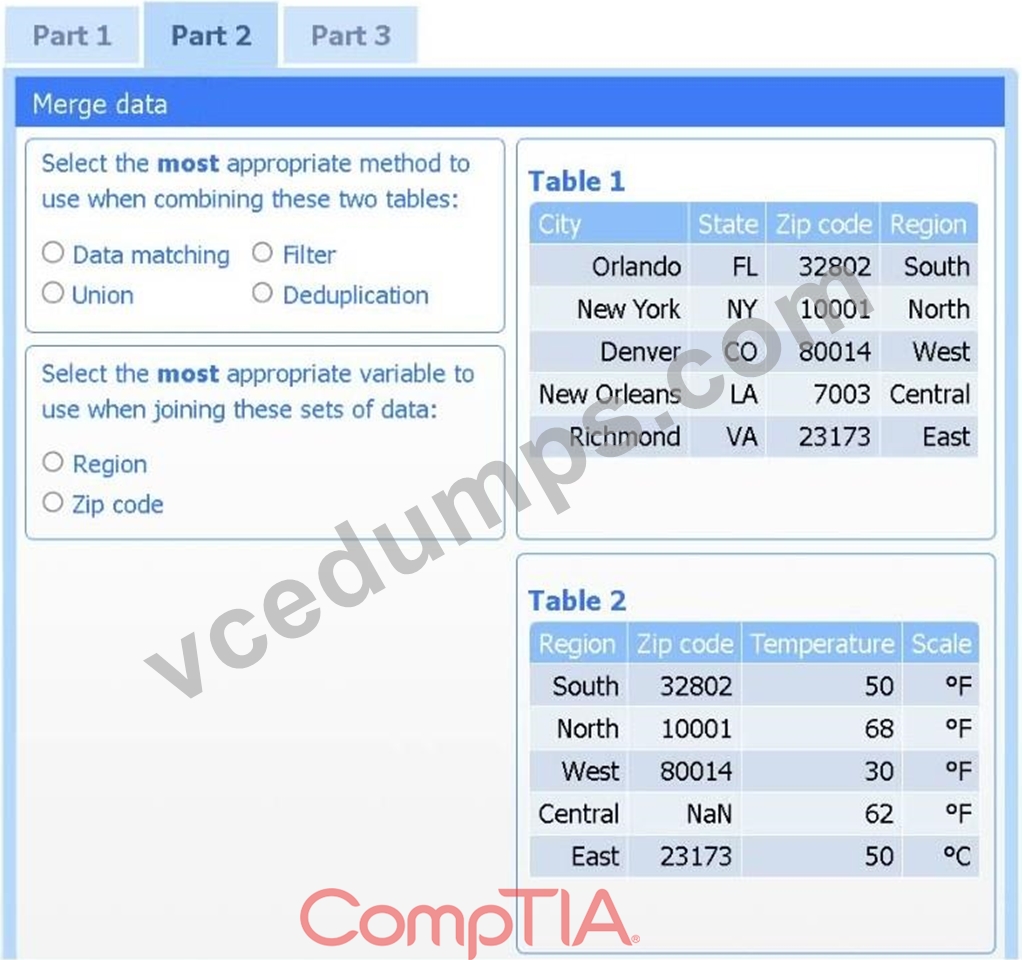
Part 2
Answer the questions to determine how to create one data set.
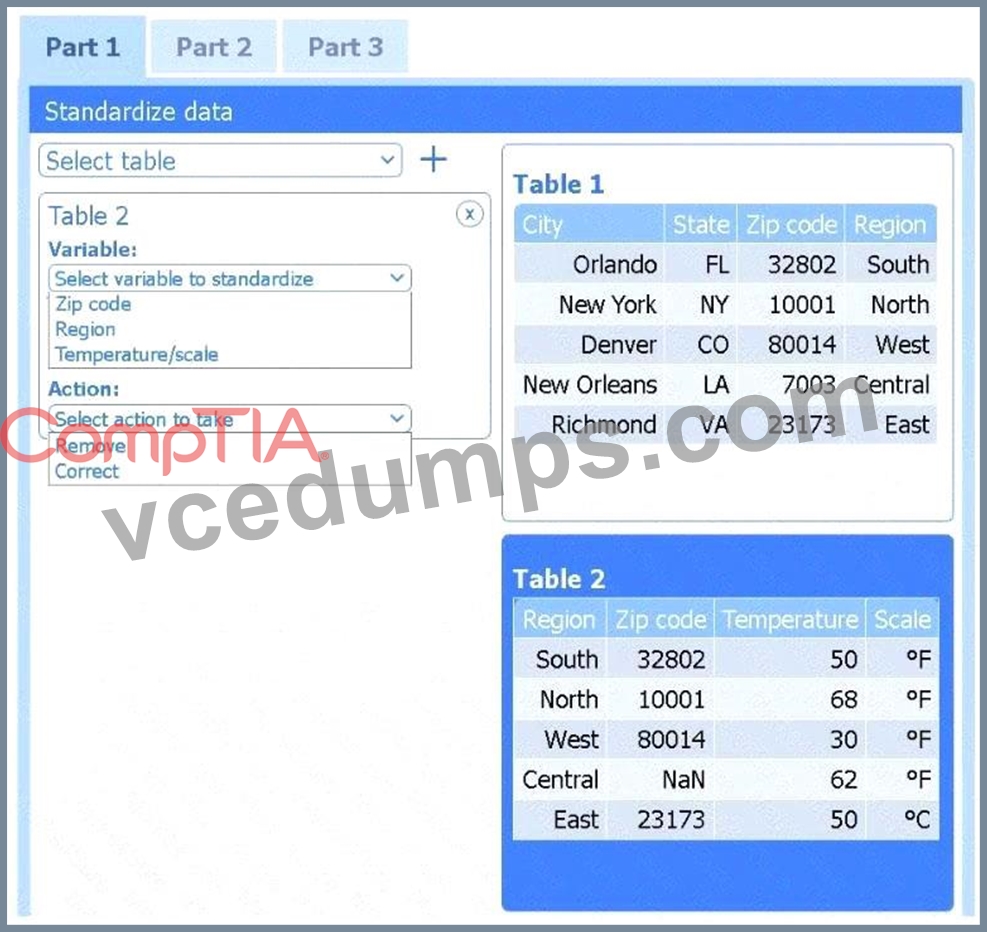
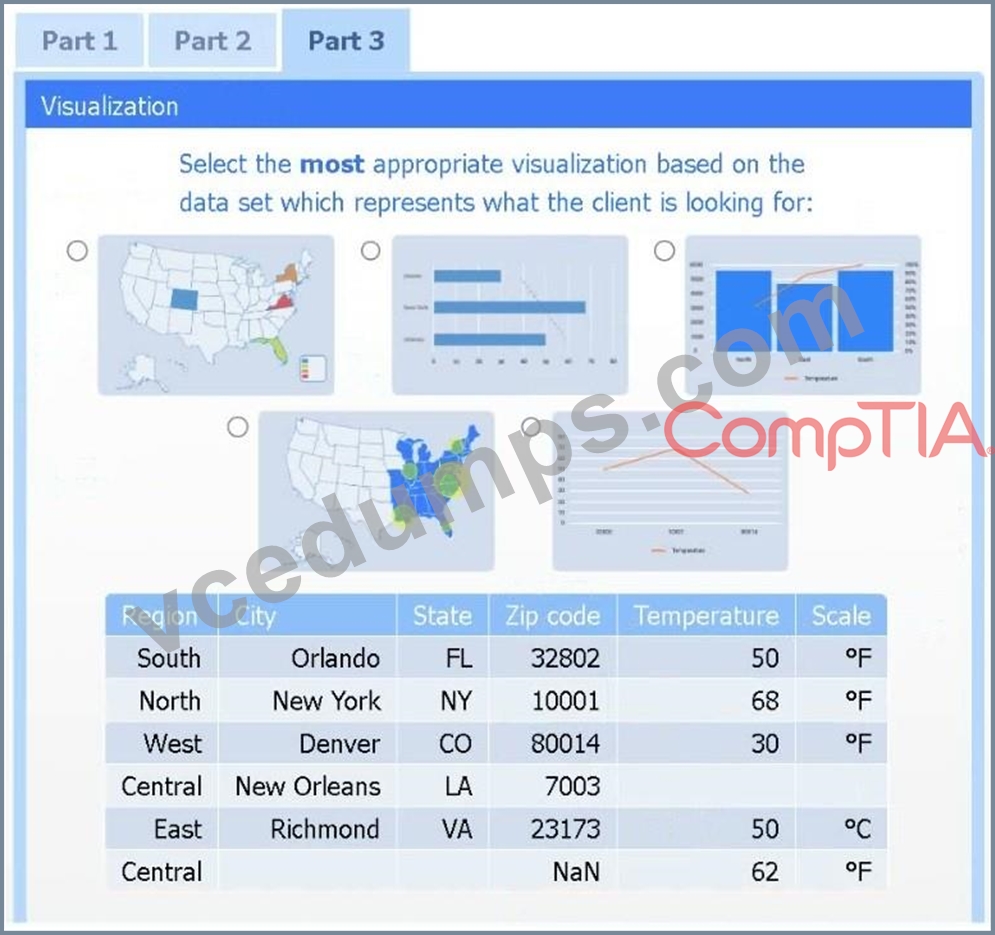
Part 3
Select the most appropriate visualization based on the data set that represents what the client is looking for.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.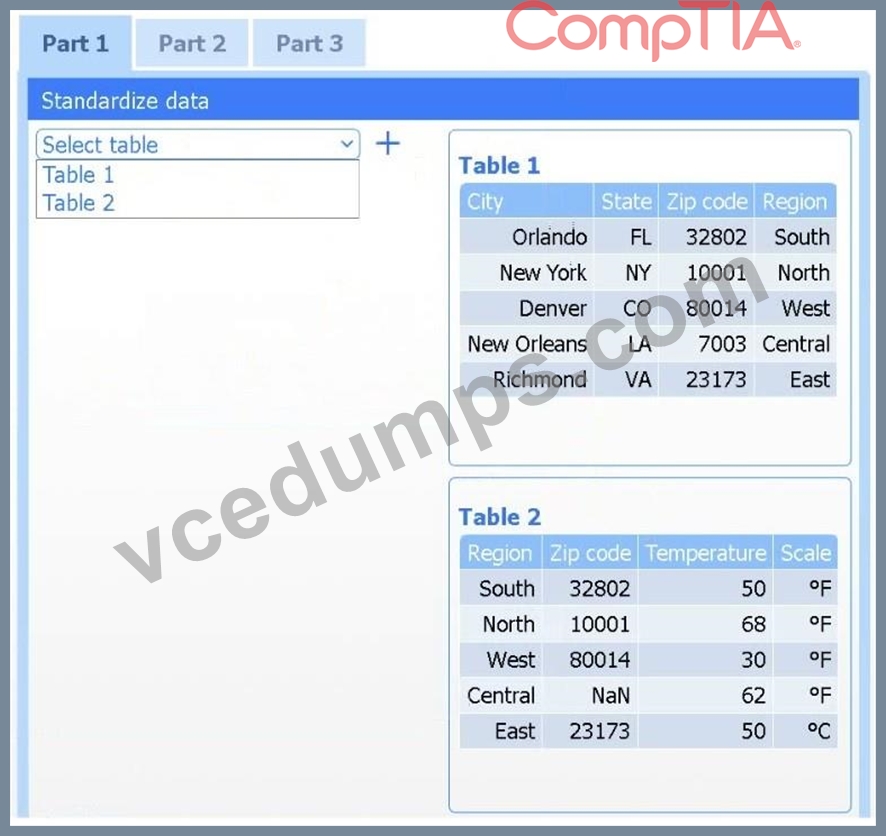
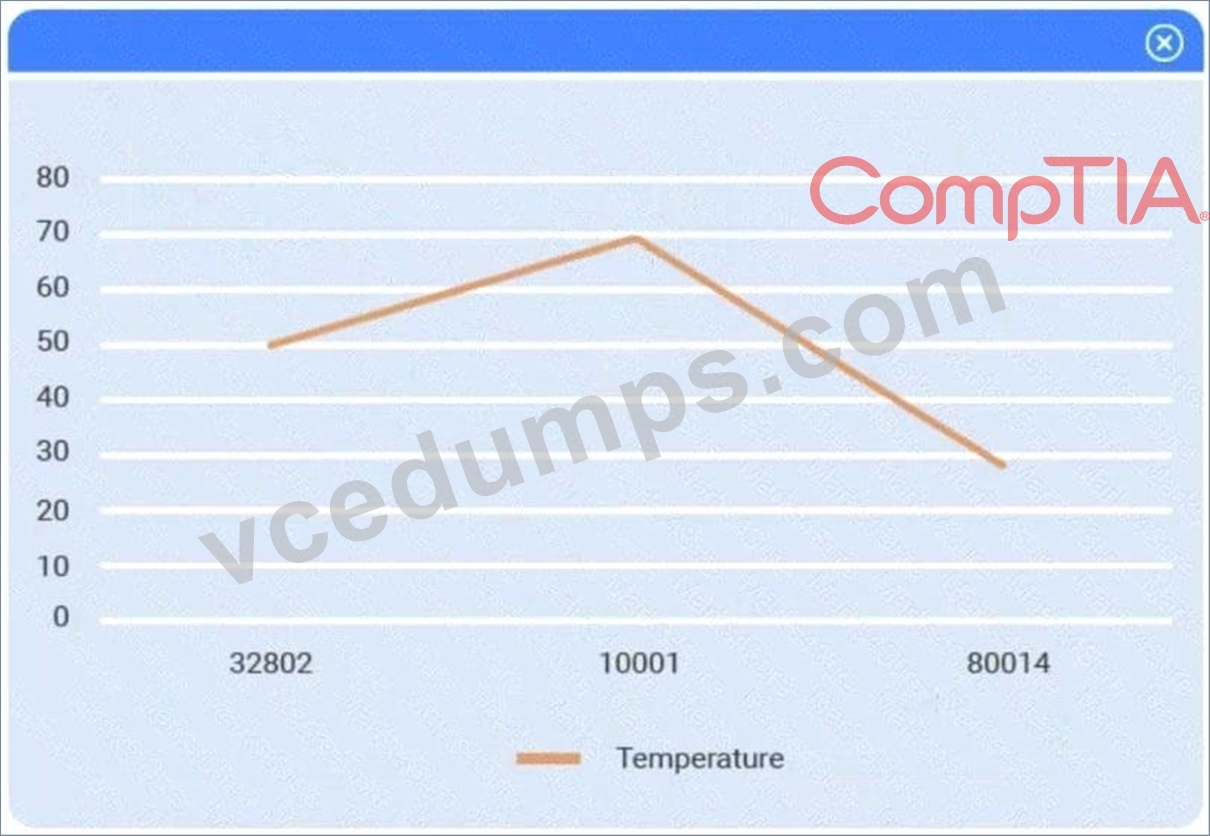
Answer:
Explanation:
See explanation below.
Explanation:
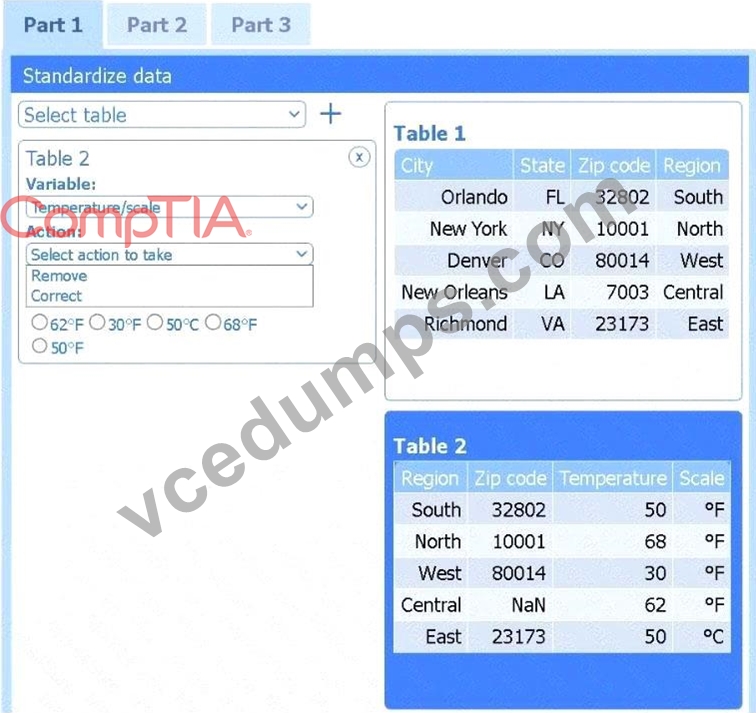
Part 1
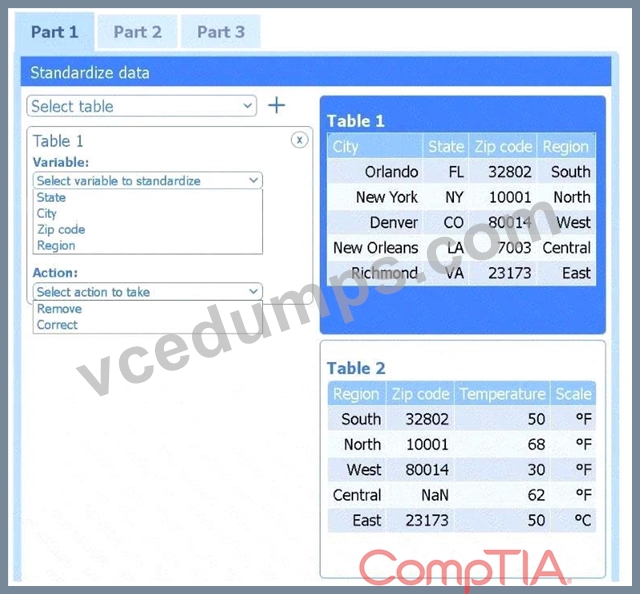
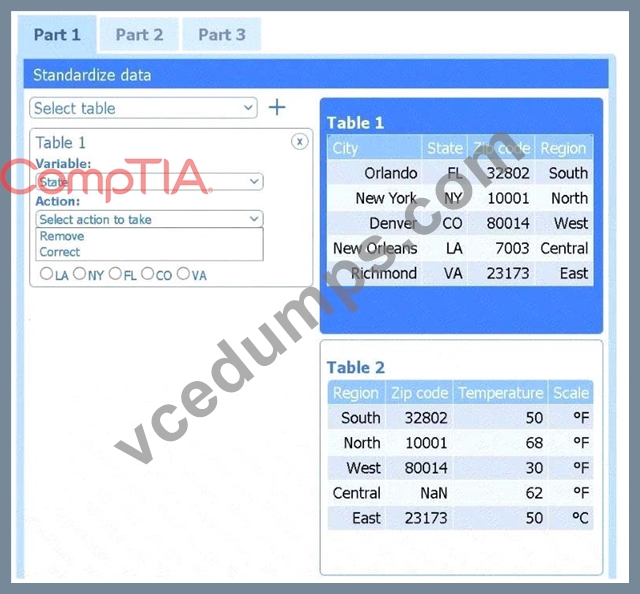
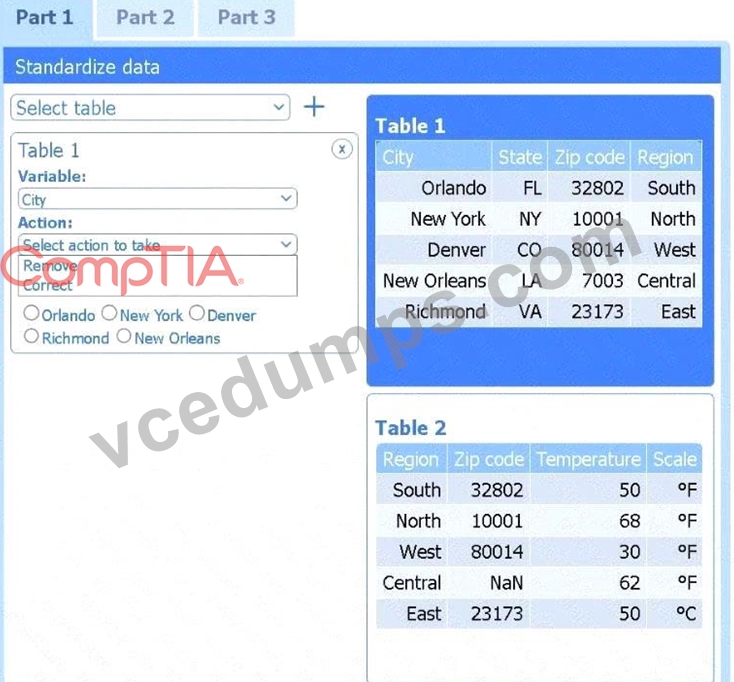
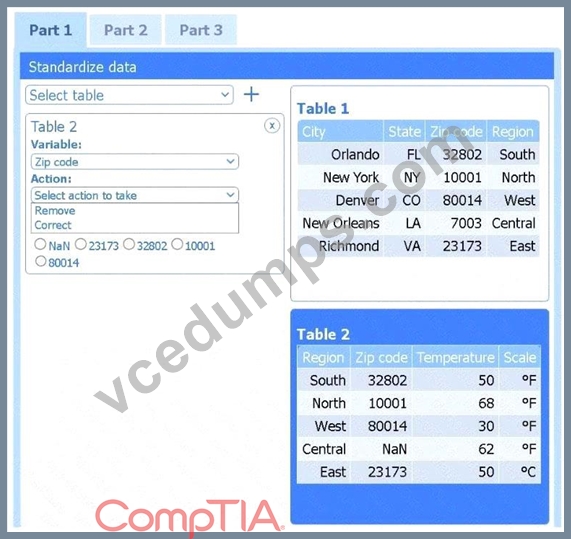
Select Table 2. Table 2 contains mixed temperature scales (°F and °C) that must be standardized before visualization.
Variable: Temperature/scale
Action: Correct
Value to correct: 50 °C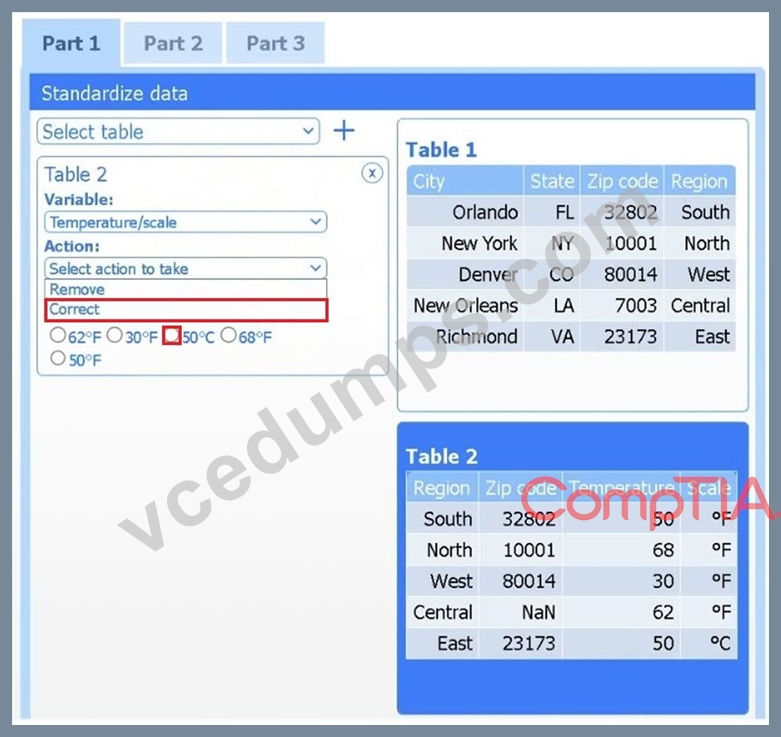
Part 2
Method: Data matching
Join variable: Zip code
You need to merge the two tables by aligning matching records, which is a data-matching (join) operation, and ZIP code is the shared, uniquely identifying field linking each region's weather reading to its city.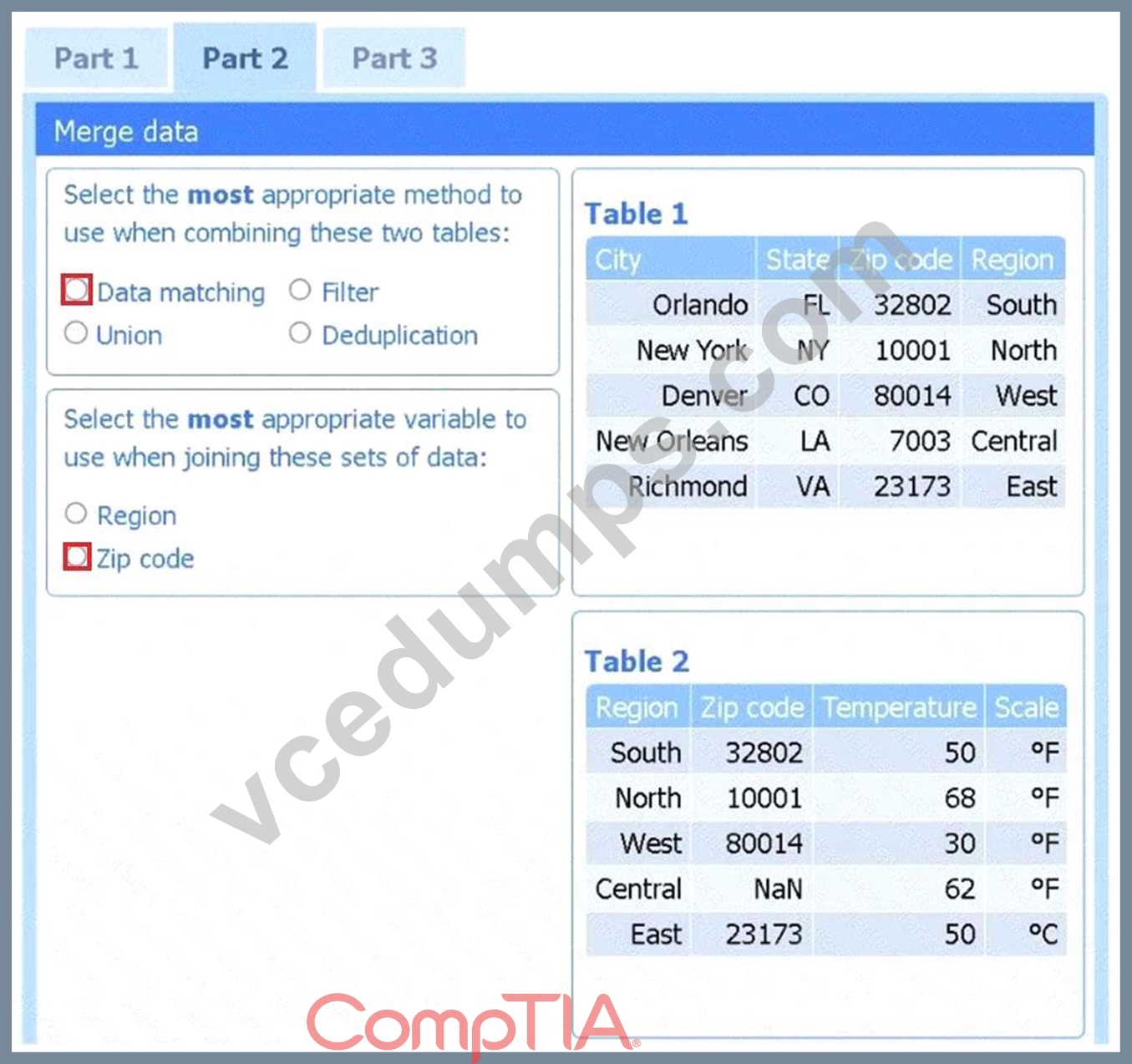
Part 3
Choose the choropleth map (the first option).
A choropleth map best shows geographic variation in temperature by coloring each state (or region) according to its recorded value. This lets the client immediately see where the highest and lowest temperatures occur across the U.S. without distracting elements like bubble size or combined chart axes.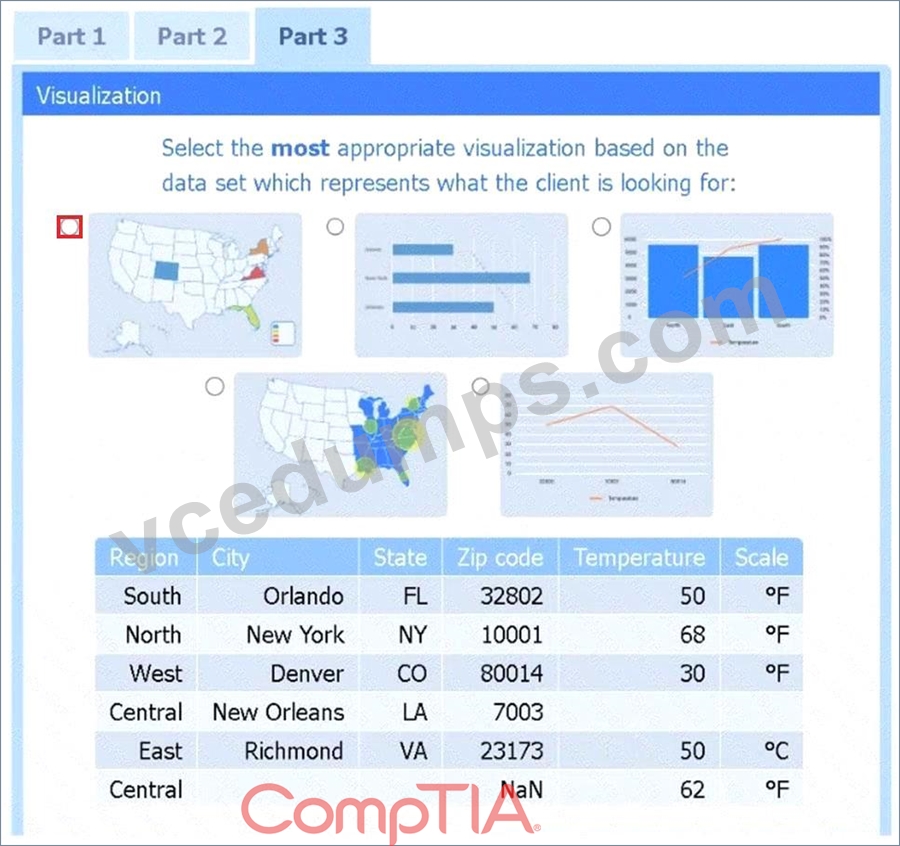
NEW QUESTION # 64
Which of the following types of machine learning is a GPU most commonly used for?
- A. Tree-based
- B. Natural language processing
- C. Deep learning/neural networks
- D. Clustering
Answer: C
Explanation:
# GPUs (Graphics Processing Units) are optimized for parallel computations, which are essential for training deep neural networks. These models involve massive matrix operations across multiple layers, making GPUs significantly faster than CPUs in deep learning tasks.
Why the other options are incorrect:
* B: Clustering (e.g., k-means) can benefit from acceleration but doesn't usually require GPU-level computation.
* C: NLP tasks may use GPUs if they involve deep learning (e.g., transformers), but the correct choice is the model type.
* D: Tree-based models (e.g., decision trees, random forests) typically run efficiently on CPUs.
Official References:
* CompTIA DataX (DY0-001) Study Guide - Section 4.3:"Deep learning models, such as neural networks, are computationally intensive and commonly require GPUs for efficient training."
-
NEW QUESTION # 65
Which of the following is the naive assumption in Bayes' rule?
- A. Normal distribution
- B. Independence
- C. Uniform distribution
- D. Homoskedasticity
Answer: B
Explanation:
# In the context of Naive Bayes classifiers, the "naive" assumption refers to the conditional independence of features given the class label. That is, the model assumes each feature contributes independently to the probability of the output class, which simplifies the computation of probabilities.
Why the other options are incorrect:
* A: Normal distribution is often assumed for continuous variables, but it's not the naive assumption in Bayes' rule.
* C: Uniform distribution refers to equal probability across outcomes, not used here.
* D: Homoskedasticity is related to constant variance in regression, not Bayesian classification.
Official References:
* CompTIA DataX (DY0-001) Study Guide - Section 4.1:"Naive Bayes assumes all features are conditionally independent given the target class, which allows for efficient computation."
-
NEW QUESTION # 66
Which of the following is a key difference between KNN and k-means machine-learning techniques?
- A. KNN performs better with longitudinal data sets, while k-means performs better with survey data sets.
- B. KNN operates exclusively on continuous data, while k-means can work with both continuous and categorical data.
- C. KNN is used for classification, while k-means is used for clustering.
- D. KNN is used for finding centroids, while k-means is used for finding nearest neighbors.
Answer: C
Explanation:
# K-Nearest Neighbors (KNN) is a supervised machine learning algorithm used primarily for classification and regression. It labels a new instance by majority vote (or averaging, in regression) of its k-nearest labeled neighbors.
# k-Means is an unsupervised learning algorithm used for clustering. It partitions unlabeled data into k groups based on feature similarity, using centroids.
Thus, the key difference is in their purpose:
* KNN # Classification (Supervised)
* K-Means # Clustering (Unsupervised)
Why the other options are incorrect:
* A: Both can technically operate on continuous or categorical data (with preprocessing).
* B: This is not a meaningful or standardized distinction.
* C: This reverses the actual roles. k-means finds centroids; KNN finds nearest neighbors.
Official References:
* CompTIA DataX (DY0-001) Official Study Guide - Section 4.1 (Classification vs. Clustering):"KNN is a supervised learning algorithm for classification tasks. K-means is an unsupervised clustering technique that groups data by proximity to centroids."
* Data Science Handbook, Chapter 5:"One key distinction: KNN uses labeled data to classify or regress; k-means uses unlabeled data to identify groupings."
-
NEW QUESTION # 67
......
As the name suggests,web-based CompTIA DY0-001 practice tests are internet-based. This practice test is appropriate for usage via any operating system such as Mac, iOS, Windows, Android, and Linux which helps you clearing CompTIA DY0-001 exam. All characteristics of the Windows-based CERT NAME practice exam software are available in it which is necessary for CompTIA DY0-001 Exam. No special plugins or software installation is compulsory to attempt the web-based CompTIA DY0-001 practice tests. In addition, the online mock test is supported by all browsers.
DY0-001 Reliable Test Voucher: https://www.vcedumps.com/DY0-001-examcollection.html
- DY0-001 Valid Test Voucher ???? DY0-001 Test Guide ⛽ Exam DY0-001 Study Solutions ???? The page for free download of ➥ DY0-001 ???? on ➤ www.troytecdumps.com ⮘ will open immediately ????DY0-001 Certification Practice
- DY0-001 Latest Braindumps Ebook ???? DY0-001 Latest Braindumps Ebook ☘ DY0-001 New Braindumps Pdf ???? The page for free download of ( DY0-001 ) on ▷ www.pdfvce.com ◁ will open immediately ????Test DY0-001 Preparation
- Free DY0-001 Exam Dumps ???? Valid DY0-001 Torrent ???? New DY0-001 Exam Topics ???? Search for ➤ DY0-001 ⮘ and download it for free on ⏩ www.prepawaypdf.com ⏪ website ????Exam Dumps DY0-001 Provider
- Well-Prepared DY0-001 Exam Price - Leading Offer in Qualification Exams - Accurate DY0-001 Reliable Test Voucher ???? Download 「 DY0-001 」 for free by simply searching on 《 www.pdfvce.com 》 ????New DY0-001 Exam Topics
- 100% Pass 2026 CompTIA DY0-001: CompTIA DataAI Certification Exam Authoritative Exam Price ⚾ Search for ( DY0-001 ) and download it for free on 【 www.pass4test.com 】 website ????Test DY0-001 Engine
- 100% Pass Quiz 2026 CompTIA Accurate DY0-001: CompTIA DataAI Certification Exam Exam Price ❕ Open 《 www.pdfvce.com 》 and search for ➤ DY0-001 ⮘ to download exam materials for free ????Exam Dumps DY0-001 Provider
- Unparalleled DY0-001 Exam Price, Ensure to pass the DY0-001 Exam ???? The page for free download of ➡ DY0-001 ️⬅️ on ☀ www.prepawayete.com ️☀️ will open immediately ❗DY0-001 New Braindumps Pdf
- New DY0-001 Exam Topics ✳ DY0-001 Latest Test Dumps ???? DY0-001 Valid Dump ???? Download [ DY0-001 ] for free by simply entering ⮆ www.pdfvce.com ⮄ website ????New DY0-001 Test Cram
- CompTIA DY0-001 Exam Questions – Secret To Pass On First Attempt ???? Easily obtain free download of ➤ DY0-001 ⮘ by searching on ➡ www.examcollectionpass.com ️⬅️ ????Test DY0-001 Engine
- Free DY0-001 Exam Dumps ???? DY0-001 Test Guide ???? Test DY0-001 Preparation ???? Search for [ DY0-001 ] on ▛ www.pdfvce.com ▟ immediately to obtain a free download ????Free DY0-001 Exam Dumps
- Valid DY0-001 Mock Exam ???? Interactive DY0-001 Questions ???? DY0-001 Valid Dump ???? Search for ⇛ DY0-001 ⇚ and obtain a free download on ▶ www.prep4away.com ◀ ????DY0-001 Examcollection Dumps Torrent
- www.stes.tyc.edu.tw, sidneyxhrb137617.pennywiki.com, aishaueft188909.bloggip.com, bookmarkssocial.com, reallivesocial.com, socialwebconsult.com, dillanvbgq646666.wikiparticularization.com, bookmarklogin.com, www.stes.tyc.edu.tw, tasneemnbpt455497.wikigop.com, Disposable vapes
BONUS!!! Download part of VCEDumps DY0-001 dumps for free: https://drive.google.com/open?id=1DjqMfz_GyalqsFXoW29_l6qOyMxFJdB3
Report this wiki page